Blog entries
06/24/25
League of Legends project (part 2)
If you haven't seen the first League blog post, please check that out first!
Note: I'm going to be more in-depth about champion select. If you aren't average to high elo, sorry!
I'll try to explain the best I can.
Okay. So TLDR from last time, I made a webapp where you can insert champions from champion select, and it will show you the best champions to pick using ML inference.
Sounds great? No. It was absolutely trash.
There were many, many issues with this, and hindsight hit like a truck on this one.
-
Issues:
- I made the embedding size (aka vocabulary of champions) a subset of all champions. I had the cutoff at 0.15% pickrate. At the time, I thought I was being smart by shaving off on the model size (Makes embedding layers 50% to 80% smaller!). However, if a rare champion is picked, you literally cannot run the model. (Which I thought wouldn't happen, but it actually did in the test games with the enemy picking Zoe jungle!)
- The user has to manually input the champions with lane assignments into the app. Manually inputting the
champion takes too long, is difficult, and is likely to get wrong.
For example, lets say the enemy first picked Yorick. Unfortunately, we have to assume it's a top-lane pick. But there's still a good (albeit smaller) chance they are jungle. But we have to lock in the Yorick pick top for the ML model. This would make the app to suggest a top-yorick counter, which could then in-turn be counterpicked by the actual enemy top.
This makes us have to meta-game and figure out their bluff, and pick it for jungle instead. By the time the player figures this out, the player already used up their 20 seconds and can't even use the app. :( - The partial winrate model has a massive bias issue. It's hard to explain so I'll use an example. Let's say there's a champion like Dr. Mundo. He's super tanky. So tanky infact, he has a 80% winrate. OMG!! With this, in our ML model, it shows Dr. Mundo as the top suggestion. The model learned that all games with Dr. Mundo is practically always winning... UH OH! DO YOU HEAR THAT??? *SNIP SNIP* OH NO!!! The enemy picked Gwen!!! THE ONE AND ONLY TOPLANER THAT DOES PERCENT MAX HEALTH TRUE DAMAGE AND ABSOLUTELY DESTROYS TANKS!!! and the game is lost. In situations with champions like Dr. Mundo, you would only pick him IF the enemy already picked a non-Gwen toplaner.
Imagine we are playing a food-character fighting simulator. You pick to play as a giant block of cheese. This is an easy pick because big cheese = super smelly = wrecks every other food but then the enemy suddenly picks the stainless-steel-cheese-grater character.
Um, okay I'll stop it there with the analogies. Basically, the model learns to assume Gwen will never be picked since most games with Mundo do not have a Gwen on the enemy side.
Anyways, okay. So first, let's start with the manual picking issue. So we can hookup to the query the rest api of the league client. This is not endorsed by Riot but whatever. I used a neat table showing all the endpoints. To make the actual query, you need the auth token and the port of the league client process. So I tried to make a website that looks at all the user's running processes and find the associated access tokens and ports and yea, if that was allowed we would not open our browsers.
Plan B: I decided to learn Electron because I thought that would be easy. I was wrong, but that's okay.
I decided to ditch the league process polling logic because I couldn't find a solution that'd work on all systems. Instead, league also stores this information in a lockfile in the installation directory.
So here's the layout:
- Electron App
- Poll for league client
- Poll for league client's champion select data
- Use the data to compute the best picks and render.
So now that we have an auto-input setup, let's fix the algorithm. Here is the million RP question, "What if we could somehow simulate variations of future picks, and just assume the worst-case scenario?"
And the million LP answer is: A Monte Carlo Tree Search! Specifically, a MCTS but with a ML inferencing for the simulation step. (The same algorithm used for AlphaGo!)
I also retrained the models with a full vocabulary embedding size. It took like an hour to train but the acc. was pretty much the same as before at 55%ish. I also trained it on missing picks as it would be found in champ-select. For the Monte Carlo, I also made the simulations simulate according to a single or double pick accordingly, which was another issue mentioned in the last blog post. I had a really hard time hooking everything up because it was hard to test but I managed. I created the ONNX model and set that up. Then, I finally tried it out.
Here's a rough-draft of the app:
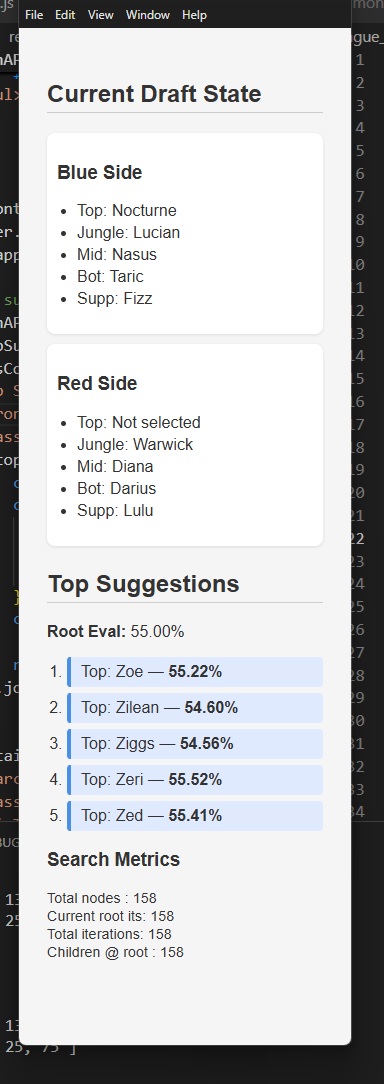
Note: We don't actually have the data to know what lanes the enemies are. I trained the model with shuffled enemy lane positions so we could use it as is. I just forgot to delete the placeholder text.
I also forgot to reorder the suggestions on change.
And this brings us to present time.
Concluding thoughts: the suggestions are not good. This is likely due to uniform randomly picking the expansion node. There is a lot of benefit to be had from simulating the more likely picks since we are running out of time in the simuation. I'll make those updates and make another post.
06/07/25
Biologically-inspired Neural Network
For a long-time now, I have been deeply unsatisfied with the current state of neural networks and specifically LLMs. The thing that bothers me the most are people saying things like, "OMG these chatbots like ChatGPT are so good at thinking!!!", stating how human-like they are. However, they do not think like humans do.
Here is the clear issue with neural networks:
- They are first trained, then run. They cannot perform both at the same time, thus they cannot learn in the traditional sense through experiences.
- They need a lot of data.
- They are not time-dependent. They are simply input-output machines. Unlike LLMs, biological brains never stop thinking, even when sleeping.
I'm not saying LLMs are bad. In fact, I use ChatGPT all the time for coding. It just bothers me they are branded as assistants when they are more like tools.
Recently, I came across a paper released by Sakana AI called the Continuous Thought Machine. It's an incredible paper and rethinks the traditional methods of neural networks.
Putting it really really simply, they basically made a classical feed-forward network but the main difference is that it loops the output nodes back into the input nodes. The output nodes are redirected back into the input to continue "thinking". This process repeats until a specific node is high enough. This serves as the model's confidence level with their answer. This makes the runtime indeterminant, but their paper shows incredible results.
If this could be combinded with some method of dynamic learning, to replace backpropagation, it could be a massive breakthrough where we could have true human-like AI.
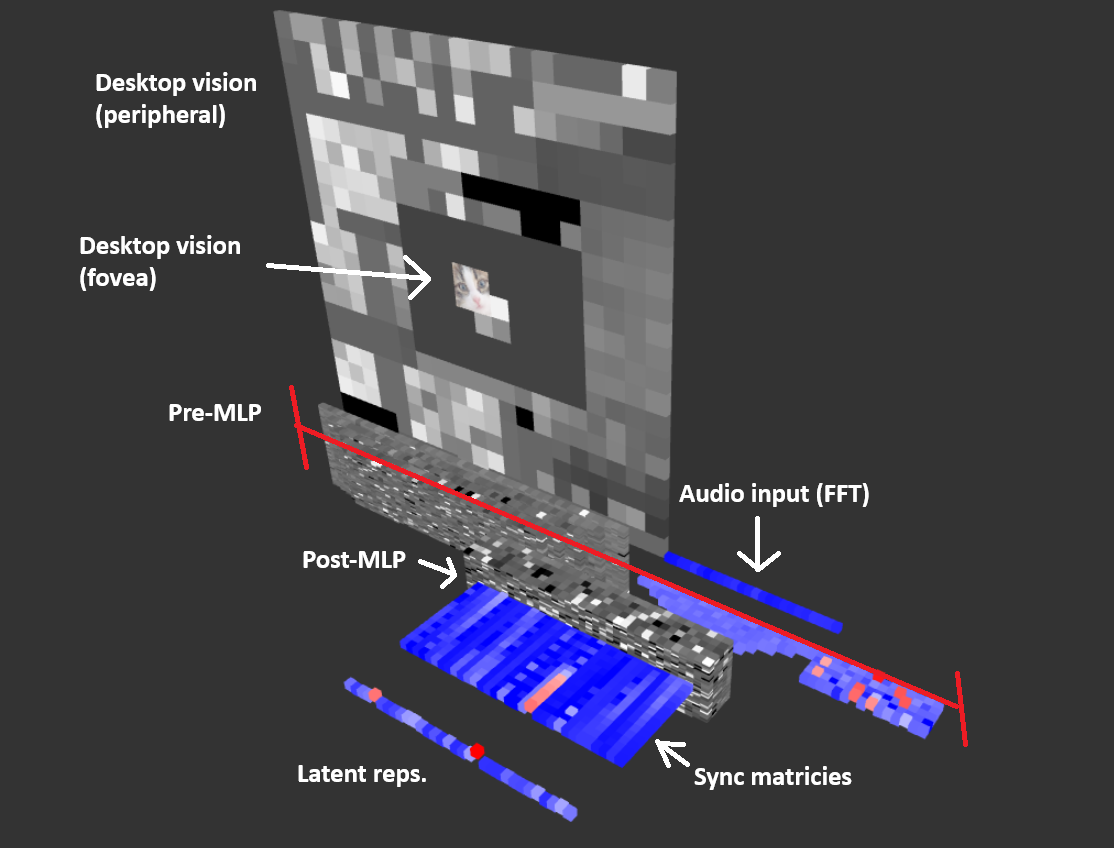
With this, I came up with my own biologically-inspired network:
Here is the architecture:
- Looping MLP. This will serve a similar role as the frontal cortex.
- Biological neuron simulation instead of linear function with activation. Specifically the FitzHugh-Nagumo Model, which is a simplified version of the Hodgkin-Huxley model.
- Duel-channel input stimuli outputting to both a predictive coding and a dense network. The predictive coding network will serve as the ventral stream stemming from the visual cortex. This acts as the "What" pathway. The dense network will serve as the dorsal stream. This acts as the "Where/How" pathway. Traditionally, this should be hooked up to eye movements, but I'll have to do some testing for that later.
- Dynamically training predictive coding network using output nodes. This would serve to train the "What" pathway to learn to predict.
- Dynamic neuron weight updates via systems to act as forms of neuroplasticity. This would serve to train the "How" pathway.
So here's my take. The primary goal of the biological brain is to predict the future. The better you can predict the future, the better you can plan. The better you can plan, the more energy you can save / energy you can earn. If you see bear footprints, you need to predict there could be a bear nearby, otherwise, you may be in danger. If you end up seeing the bear too late, you would have to enter your flight or fight reflex which wastes valuable energy when all of this could have been avoided if you had predicted it from the start.
There's a lot here and honestly it seems pretty unlikely to be fruitful but I'll keep trying. I've implemented all parts except the PC model and the last bullet point. Here is a teaser image:
05/14/25
League of Legends project:
So this past month, I've been working on the league project. I haven't gone into the details before so I'll explain the purpose of the project.
The idea is: I'm sick and tired of losing my league of legends games.
While I can just get better, I feel like most games I lose, the games were unwinnable. You could have put faker in my place and we still would have lost. This is where my project comes in. What my project aims to do is to assist the user in picking their champion; to maximize their chance of winning, even before the game starts.
Some may ask, "Why not just look at the most meta champions (the strongest characters in the current game version) and just play that?
Here's the issue:

You could always pick Riven, and assuming you play pick-ban well to avoid getting counter picked, it would be okay. However, there is most likely a better champion to play in that given scenario.
If the rest of your comp is well-rounded, going a split push champion would be great. Or if your team needs a frontliner, going a durable tanking champion would also be better. This applies to all other lanes as well.
I've worked on this project on and off for the past 8 years. When I first learned about neural networks in junior year of high school, I imagined a tool like this would be possible. However, the model never seems to train well. It's been about 2 years since my last attempt, so here I am to try again.
I started off with getting some data. I fetched some games from riot's api and got started (I had roughly 7000 games at this point). Before I train the pick model, I wanted to test making a winrate model first.
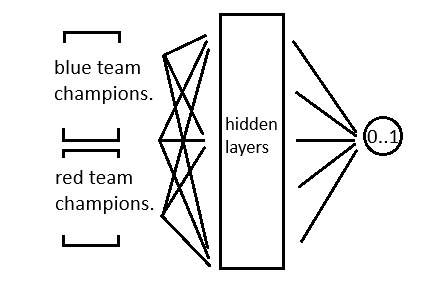
This model is simple. I input champions from team A and team B, and I output one node, which predicts the outcome of the match. Since champions are referenced with ids, I needed to encode the ids such that numerical closeness doesn't indicate champion closeness. For this, I used one-hot encodings. This expands one champion into the champions space with all zeros except the index of the champion id. So far simple stuff, and this is the same technique I used 8 years ago.
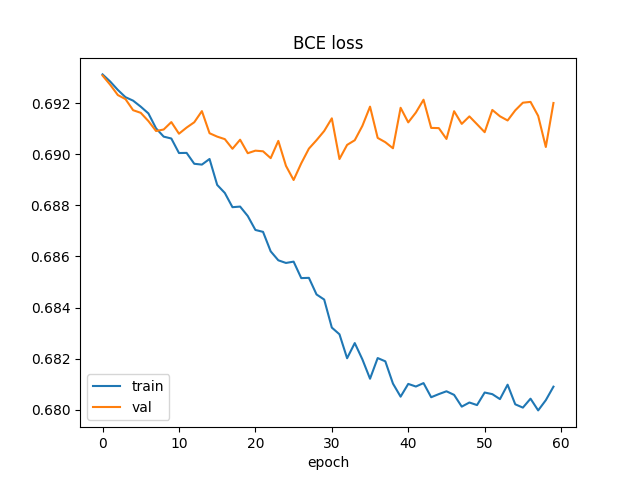
Unsuprisingly, the model wasn't very good. I had a similar result to this in high school, except I didn't have a loss graph. Back then, my friend and I built the whole model in Java from scratch and we didn't have much knowledge of neural networks back then. When we tested this, all we got for the picks were A) the most common champions at the time and B) the strongest champions at the time. It was always like Sett, Jhin, Yasuo, Ashe. At the time, I didn't check for validation loss. So I thought lower loss = good, and was lost when the model didn't work. I now realize this approch tends to strongly overfit. Back then, I used models 5,000x3 or so. It simply found the strongest champions tended to win, so it only outputed those champions.
At this point, I started thinking about how different champions are sometimes quite similar in how they play. For example, Jhin and Ashe are quite similar in that they play as utility carries. Jhin can follow up with roots, and Ashe can follow up with W slow + ult stuns. They can still provide utility to the team when behind.
Then, I learned about embedding layers. I cannot believe we did not learn this in our machine learning class.
For those who do not know what they are, it's an alternative approch for situations where you would need to
one-hot encode. Rather than expanding the champion selection to a sparse layer with width = category size,
you can instead convert the champion to a n-dimensional vector representation. You can think of this as
forming n-word descriptors for champions rather than saying the champion itself. For example, a
4-dimensional vector embedding for champions (range of 0 to 1) for Ashe could be something like:
{
"physical vs magic damage": 0.1,
"supportive vs carry": 0.7,
"damage vs utility", 0.5,
"melee vs ranged": 0.9
}
Note: we wouldn't have labels nor know the meaning of each dimension, as it is learned.
With this approch, it won't be able to recognize the picks themselves, rather, their characteristics. (In theory.)
Here were the inital results (I added stratified k-fold cross-validation):
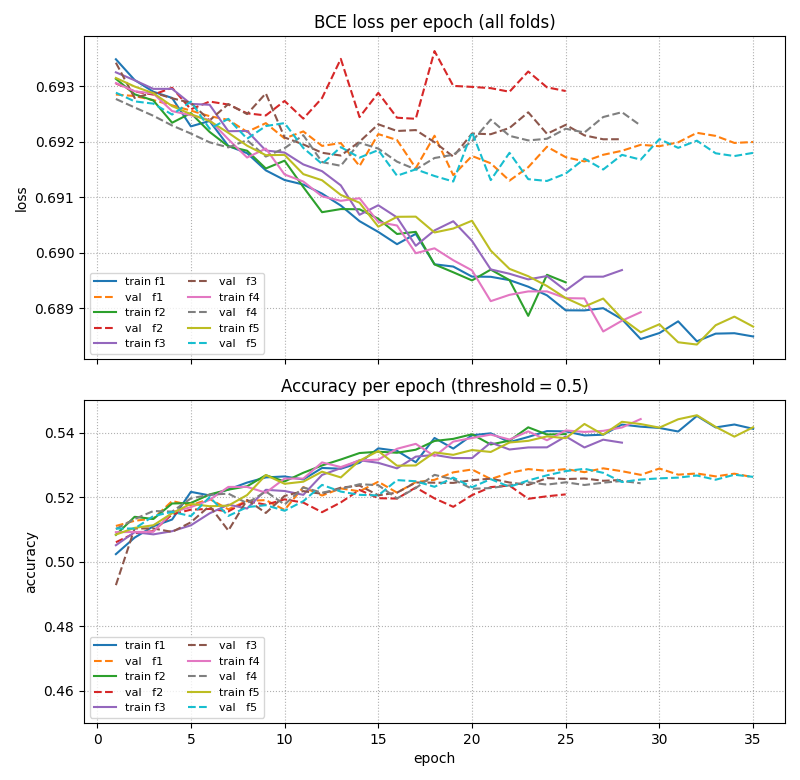
It seems like the results are worse! ahahahah.
Got more data (250,000 total matches), added dropout, weight decay, label smoothing, and tuned the model for about a week straight. Here are my results:

Awesome. I'll take that for now. Now for the pick model.
I'm still a bit unsure about the correct method for this, but I opted for one-hot encodings. I do this because there are champion specific combinations that matter for picks, which would suffer if the champions are obscured with embedding layers. (I think)
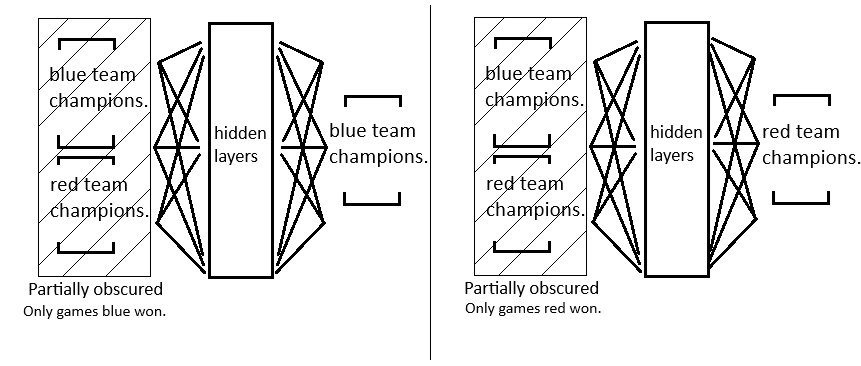
My idea is to train two models. One for maximizing for blue team, and the other for red team. I train each on only games that side won, and also augment games to also have variations where picks are incomplete. This way, the model will learn to identify the champion combinations that tend to win games.
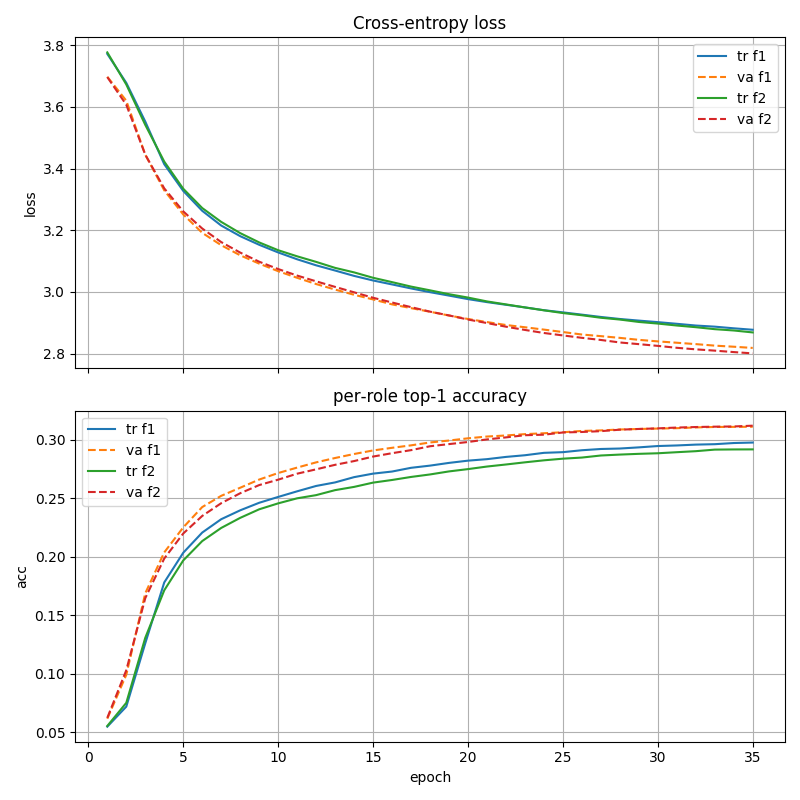
The plot looks suspiciously smooth, which I assume is due to it guessing champions that are visible, but whatever. I don't think that matters too much. I might recreate this with a bit different logic later but it seems to work fine for now.
Results:
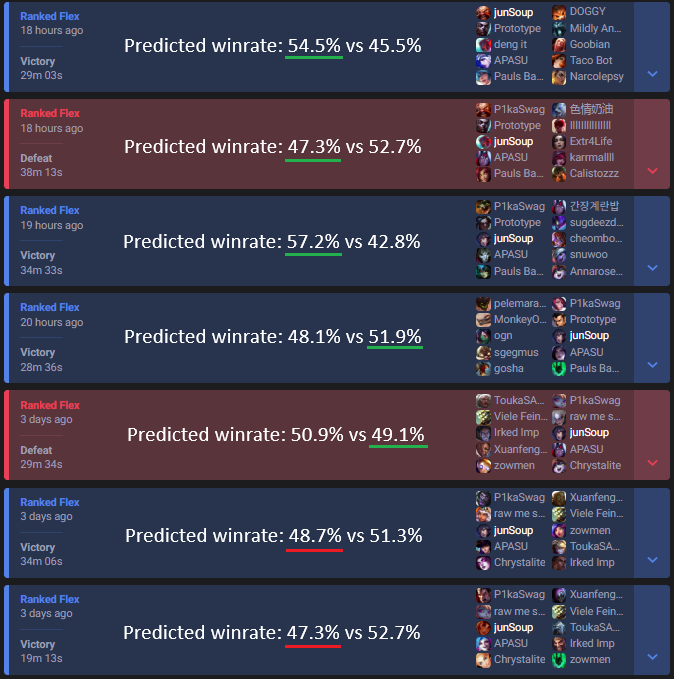
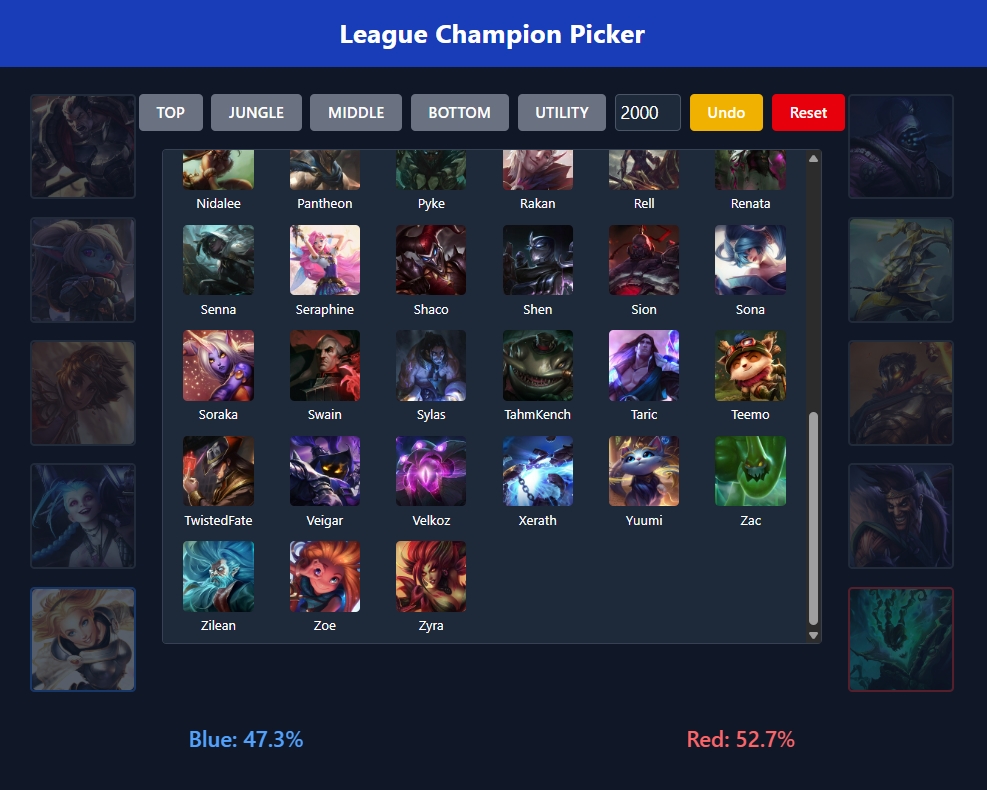
A group of friends and I played a couple games with the model. We used it to pick the best champions (when we could). We also used the model to estimate our chances to win the game.
Note: On the bottom lost game, the webapp I built broke so we picked whatever. For the other lost game, we didn't pick a recommended jungler because he didn't know how to play any of them. Regardless, we had fairly good picks, and won most of our games. The first two games we won despite the odds. For the other five games, our match outcome aligned with the prediction.
Concluding thoughts:
The front-end design can use some work. Currently, it takes too long to find and insert champions, leaving
little time think about which ones to pick.
Pick combinations are unaccounted for. For example, lucian + nami could have been a good pick in some games,
but by themselves they are marked as bad picks. This is a missed opportunity. This would raise my output
nodes to like 36,000 to uniquely identify each champion pair, which is rather large. Or, I could run
simulations of combinations of top-n champions. This could work, but it would take longer for inference.
All in all, I am happy with my results. If I think of better methods, I'll revisit the project.
04/15/25
Time for another blog post!
I've finished two more projects and actually put it up on github so I can show it off. They're the koi fish and apple projects. I showed the fish project to some of my friends, and one of them told me it gave him motion sickness. Cool. I also tried going on the page on a old phone, and it was super laggy. I honestly don't know how or why this happens. I thought it was due to the shader code being forced to run on non-applicable hardware but even with an empty scene, if I have hardware acceleration disabled, the page becomes unresponsive. Actually, me typing this made me realize that a page not being responsive means it's CPU limited, but whatever.
You know what, if your device so slow it can't even run an empty scene, you don't deserve to see my code. There I said it.
All jokes aside, this project really makes me want to see how far I can push the THREE.js renderer. I didn't really make this with performance in mind, although I did use mesh instancing to reduce the fish and lilypads to single draw calls. Browsing the THREE.js examples was honestly inspiring, and I thought it was so cool how it could do all that in the browser.
01/27/25
A few months have passed since the last update. I've been pretty busy with my jobs so I haven't had the energy to work on this site.
For the last couple weeks, I've had the chance to work with plain HTML + tufte.css which was pretty cool. I've had to change it slightly to meet our use cases but nonetheless it was a pretty good experience. With that, I'll continue with plain HTML on this site for a bit. After all, this website will static for the time being. I will also be quitting my software job this week and my CS tutoring job soon as well. I've decided to quit due to them not aligning with what I want to do as much as I'd like.
Another reason why I'm quitting is because my parents' restaurant business have been doing well. I've been helping out for some time now, but it looks like they will do okay without me. With this, I'll finally be free to accept work that requires relocation.
With this newly granted free time from being jobless, I'll mainly be working on my own projects. I have many projects in mind, but I'll get to them one at a time. The first project I'll be getting to work on is my [name to be deterimined league analysis tool] analysis tool. Quite the mouthfull, I know. I've been experimenting with this project on and off for the last 8 years but I've never got it to a functional stage; I'd like to change that. In addition, I'll finally make the remaining pages for this website and publish it. That'll be it for this post.
08/26/24
Okay. I give in. This may be the fastest fold in history but I'm switching the site front-end to React+tailwind. The page was looking good until I had to make a mobile dropdown. It looks good but if it takes 2+ hrs and 200 lines for anything remotely modern, it's just not worth my time. Plus, I have to make some dev sites at work so I might as well get some practice in.
For reference, Here's the dropdown I make. I'm too proud of it to just delete it without showing it off first. (It was even animated and everything!)
08/01/24
Well, time to write the first entry! I'll take this chance to write about the development of this website. At the start, I considered using vue3+vite. I thought it would be good since front-end isn't my strong suit and because I already have some experience with Vue.js. So I made a pros and cons list.
Pros of using Vue/React
- Faster load time
- Faster development time
- Faster probably everything
Cons of using Vue/React
- Struggle to understand what I wrote two months down the line
Okay, I think the choice is obvious. An added perk of not using a library is that I can say I wrote this site in plain HTML and CSS. Yeah, the choice was simple.